
Deep Learning: Activation Functions
What is an Activation Function?
Activation functions are an extremely important feature of the artificial neural networks. They basically decide whether a neuron should be activated or not. Whether the information that the neuron is receiving is relevant for the given information or should it be ignored.
Y = Activation((weights * bias) + bias)
Can we do without an activation function?
When we do not have the activation function the weights and bias would simply do a linear transformation. linear equation is simple to solve but is limited in its capacity to solve complex problems. A neural network without an activation function is essentially just a linear regression model. The activation function does the non-linear transformation to the input making it capable to learn and perform more complex tasks. We would want our neural networks to work on complicated tasks like language translations and image classifications. Linear transformations would never be able to perform such tasks.
The Activation Functions can be basically divided into 2 types-
Linear vs Non-Linear Activations
- Linear Activation Function
- Non-linear Activation Functions
Linear or Identity Activation Function
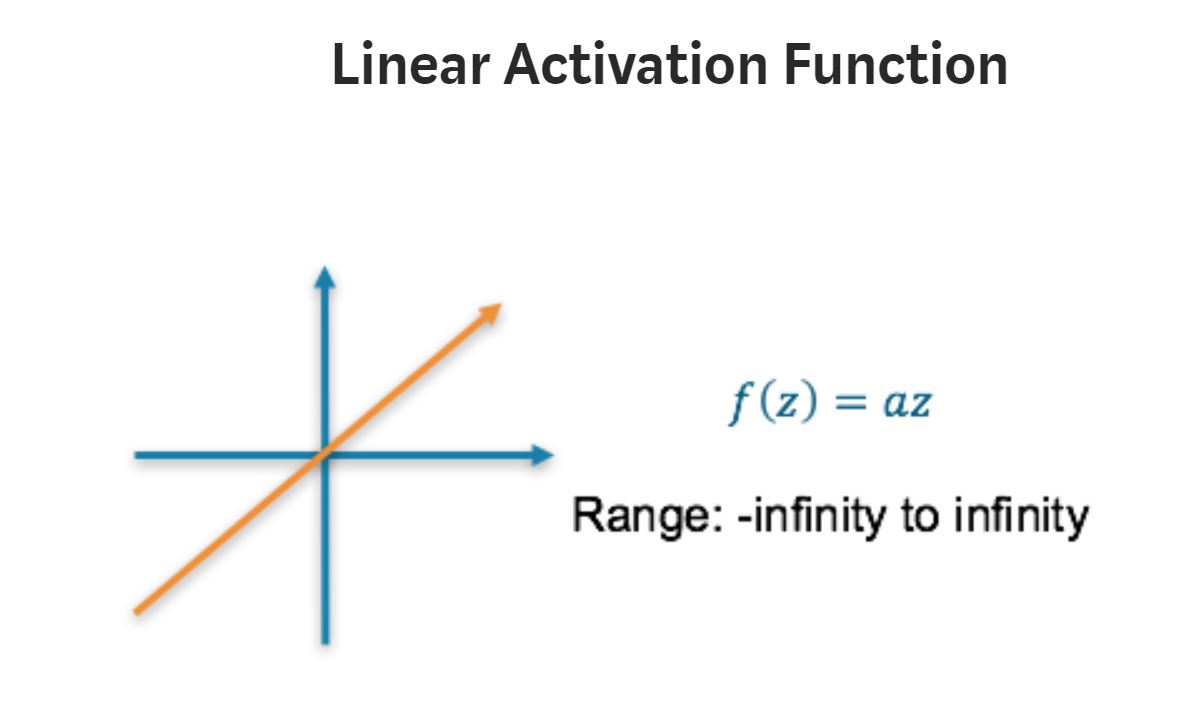
Range : (-infinity to infinity) The derivative of a linear function is constant i.e. it does not depend upon the input value x. This means that every time we do a back propagation, the gradient would be the same. And this is a big problem, we are not really improving the error since the gradient is pretty much the same.
def linear(x):
return x
Non-linear Activation Function
Neural-Networks are considered Universal Function Approximators. It means that they can compute and learn any function at all.
Sigmoid
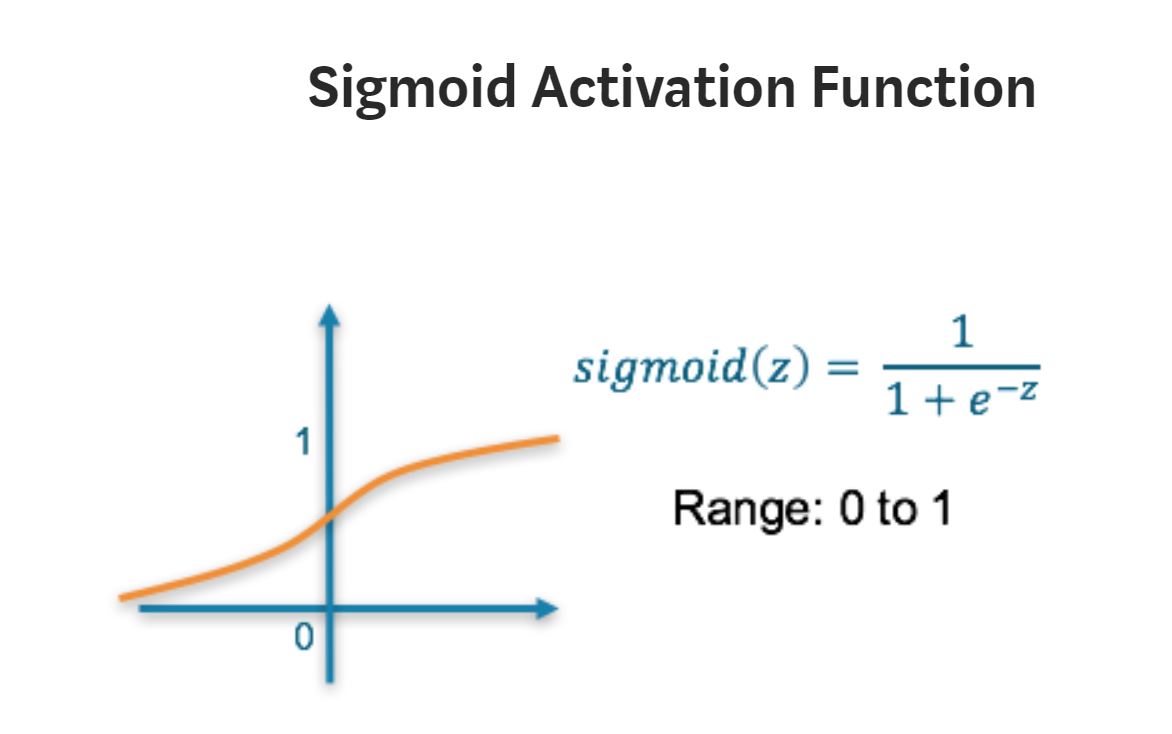
Range: (0-1 )
This is a smooth ‘S’ shaped function and is continuously differentiable. This means that in this range small changes in x would also bring about large changes in the value of Y. So the function essentially tries to push the Y values towards the extremes. This is a very desirable quality when we’re trying to classify the values to a particular class.
But, higher the values of x results very small gradients results vanishing gradient problem. As the values ranges from 0-1 it makes the gradient updates go too far in different directions. 0 < output < 1, and it makes optimization harder.
- Vanishing gradient problem
- Harder for optimization
- Kills gradients
- Slow convergence
def sigmoid(x):
return (math.exp(x)/(math.exp(x)+1))
Hyperbolic Tangent Activation Function: Tanh
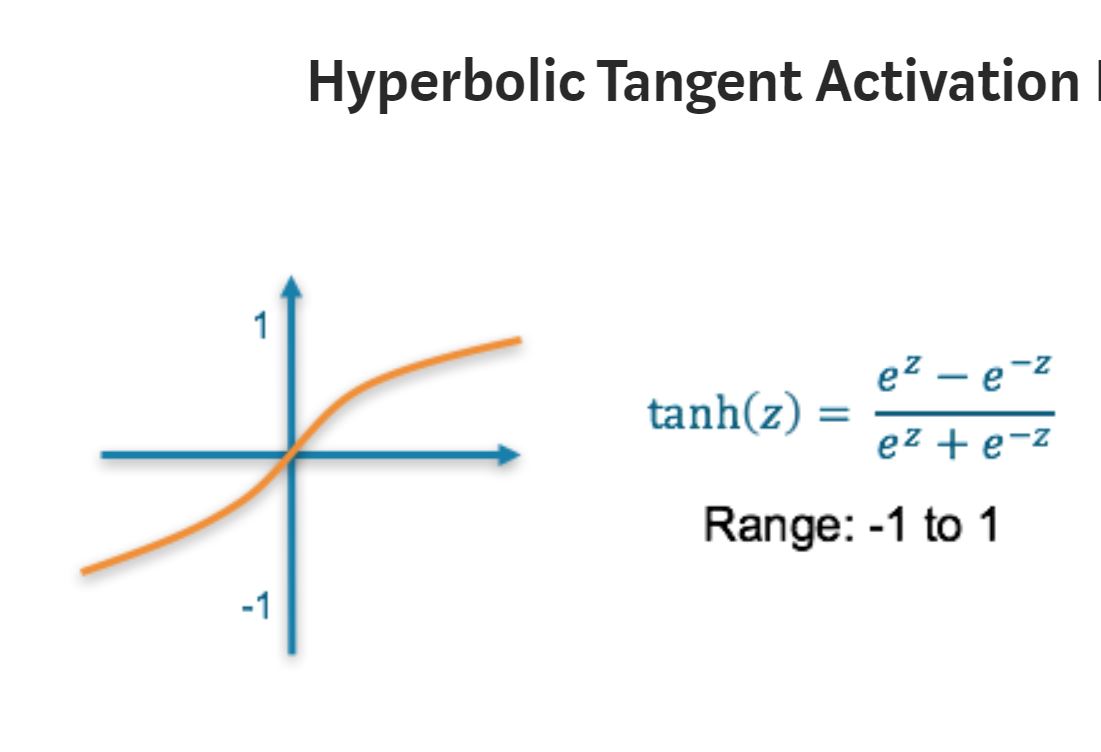
Range: (-1 to 1)
Tanh is also like logistic sigmoid but better. The range of the tanh function is from (-1 to 1). tanh is also sigmoidal (s - shaped) which is more steeper. The advantage is that the negative inputs will be mapped strongly negative and the zero inputs will be mapped near zero in the tanh graph.
- Vanishing gradient problem
- tanh function is mainly used classification between two classes.
def tanh(x):
return ((math.exp(x))-(math.exp(-x)))/((math.exp(x)+math.exp(-x)))
Rectified Linear Unit (ReLU) Activation Function
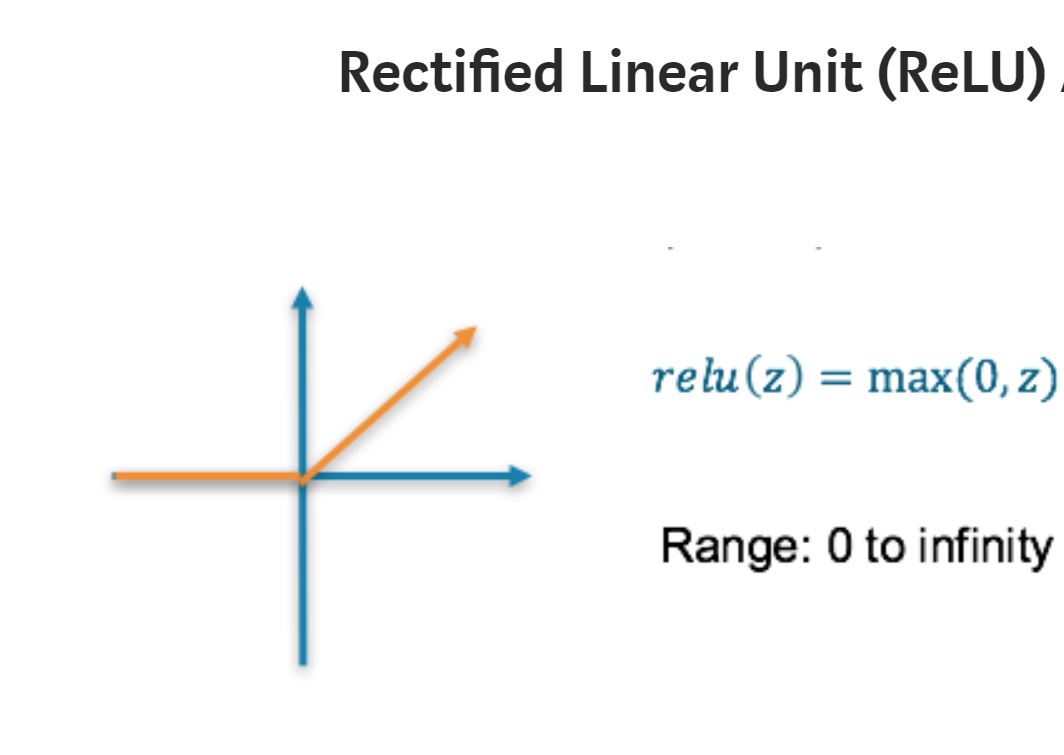
Range: [ 0 to infinity)
The ReLU is the most used activation function in the world right now.Since, it is used in almost all the convolutional neural networks or deep learning.
- As it does not allow for negative values, certain patterns may not be captured
- Values can get very large
def relu(x):
return max(0, x)
Leaky ReLU
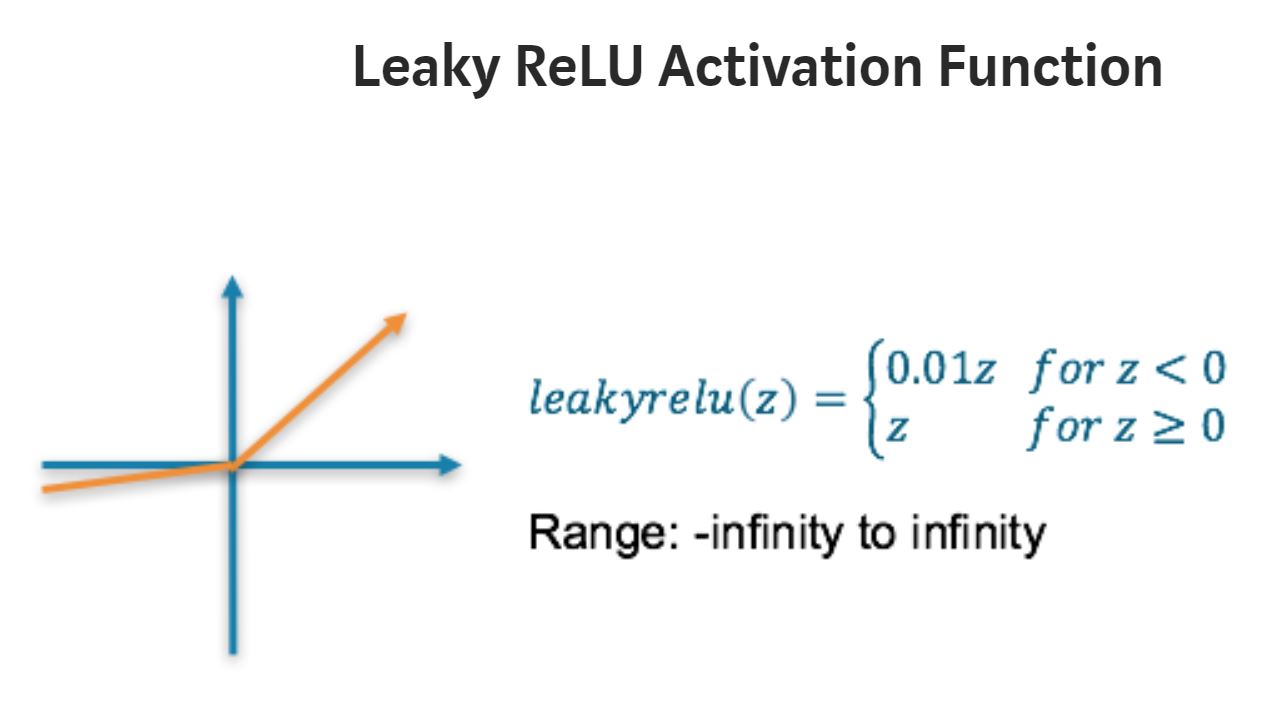
Range: (-infinity to infinity)
It is an attempt to solve the dying ReLU problem. Instead of defining the Relu function as 0 for x less than 0, we define it as a small linear component of x. It can be defined as
f(x)= ax, x<0
f(x)= x, x>=0
Here a is a small value like 0.01 or so.
- removes the zero gradient problem.
Softmax
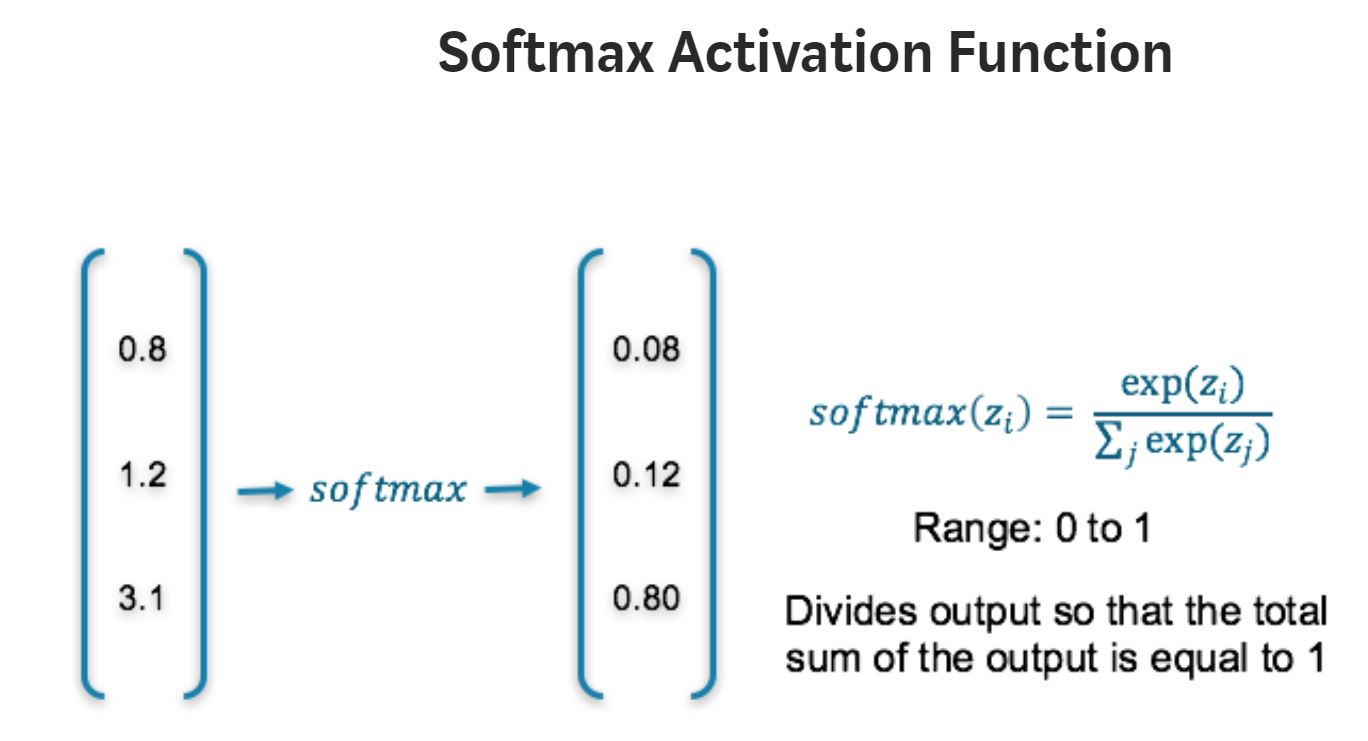
Range = (0,1)
The softmax function is also a type of sigmoid function but is handy when we are trying to handle classification problems. The sigmoid function as we saw earlier was able to handle just two classes. What shall we do when we are trying to handle multiple classes. The softmax function is ideally used in the output layer of the classifier where we are actually trying to attain the probabilities to define the class of each input.
def softmax(x):
ex = np.exp(x)
sum_ex = np.sum( np.exp(x))
return ex/sum_ex
Choosing the right Activation Function
Now that we have seen so many activation functions, we need some logic / heuristics to know which activation function should be used in which situation. Good or bad – there is no rule of thumb.
However depending upon the properties of the problem we might be able to make a better choice for easy and quicker convergence of the network.
- Sigmoid functions and their combinations generally work better in the case of classifiers
- Sigmoids and tanh functions are sometimes avoided due to the vanishing gradient problem
- ReLU function is a general activation function and is used in most cases these days
- If we encounter a case of dead neurons in our networks the leaky ReLU function is the best choice
- Always keep in mind that ReLU function should only be used in the hidden layers
- As a rule of thumb, you can begin with using ReLU function and then move over to other activation functions in case ReLU doesn’t provide with optimum results.
Resources & Acknowledgements
https://towardsdatascience.com/activation-functions-neural-networks-1cbd9f8d91d6 https://www.analyticsvidhya.com/blog/2017/10/fundamentals-deep-learning-activation-functions-when-to-use-them/